February 19, 2026



Artificial intelligence systems are no longer standalone models responding to prompts. Modern deployments increasingly resemble complex ecosystems composed of models, retrieval pipelines, orchestration layers, external tools, and data infrastructure. These architectures expand the attack surface far beyond traditional software systems.
For security practitioners, this shift introduces an uncomfortable reality: the logic of the system is partially probabilistic and controlled through language rather than code. Attackers can influence behavior not only through API parameters or malformed input but through adversarial instructions, poisoned data, and manipulated context.
In this post, I'm going to discuss how to approach penetration testing for AI ecosystems, breaking down the architecture, identifying attack surfaces, and outlining practical testing strategies for modern AI applications.
LLM's are not new in this world, infact, the first documented LLM was at MIT in 1964, a chat bot named ELIZA which was created to explore communication between humans and machines. LLM's have been used in institutions and the military for years, and in 2020 we started to see the first interfaced chat bots that we are seeing a rise in now.
Testing of LLM's has typically only been around a few years that we know of, known as "red teaming" the model, this consisted of prompt injection and jailbreaking techniques, but this has evolved with agentic AI becoming more frequent and introducing the need for penetration testing methodologies as ecosystems become more intertwined with our traditional IT stack.
We've all seen AI based chat bots, they've been around for some time now, but as AI gets introduced and further integrated into corporate infrastructure, they evolve from being a simple chat interface, to a whole ecosystem.
An AI ecosystem refers to the broader environment that surrounds and enables a model to operate in production. While a language model may be the core component, its capabilities are typically extended through multiple surrounding systems, examples being:
Together these components form a distributed stack, where the model is only one element in a larger ecosystem of other elements and tooling. Unlike traditional application stacks, AI ecosystems introduce several unique properties:
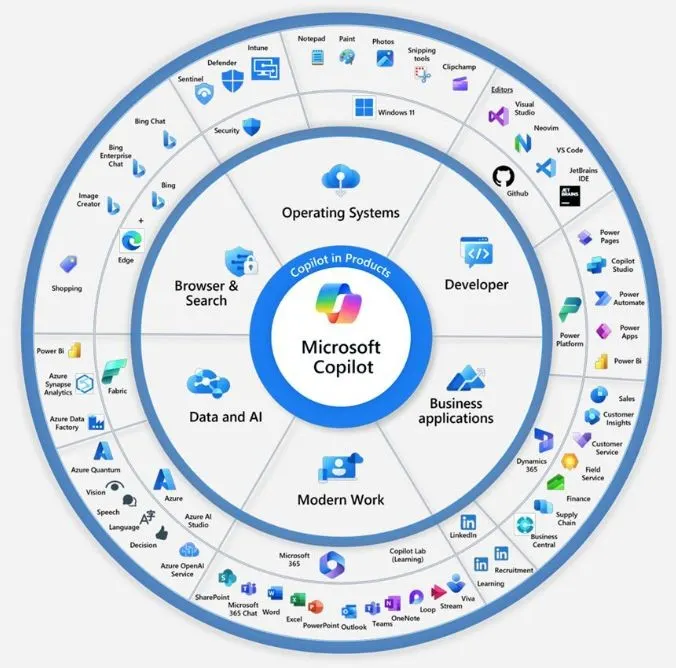
These characteristics create entirely new security challenges that traditional penetration testing methodologies were not designed to address. An example of AI ecosystem, would be Microsofts Copilot, as shown below:
The first step in testing an AI ecosystem is somewhat similar to traditional testing, we need to perform threat modelling (scoping) of the implementation to understand as much as we can about the system(s). This becomes key when assessing AI-enabled technology, as there is a lot of ambiguity with these systems, that when combined with the first-try-fallacy issues of LLM's, could make the difference between a test being a couple of weeks long to a couple of months without proper understanding of the architecture and its intricacies.
When threat modelling an AI-driven system we are looking for what the inputs are, intuit what technologies are involved and what the risks are to the implementation. There are two separate paths I like to take here, the first being to perform a more generic scope, where we would assess things like:
This is just a brief list that would give me an initial view of how the AI is implemented and it's surrounding integrations. The next step here would be to threat model the AI-driven system, where I would be looking at the following areas:
These are some high level examples of things we look at when threat modelling AI-driven systems to gain a better idea of how we can begin to think about attacking the model, its trust boundaries and any integrated tooling.
As with any penetration testing, we need a structured framework to guide us through a systematic process to identify, exploit and report vulnerabilities. These methodologies ensure consistency, thoroughness, and compliance with industry standards.
There are plenty of frameworks out there for penetration testing, such as PTES, OWASP testing guide, NIST SP 800-115, OSSTMM etc, but none of these cover testing AI ecosystems. More recently OWASP have released v1 of the OWASP AI testing guide:
https://owasp.org/www-project-ai-testing-guide/
There is also the Arcanum LLM assessment methodology (shout out to Jason Haddix and his Attacking AI course), which is typically what I follow when testing:
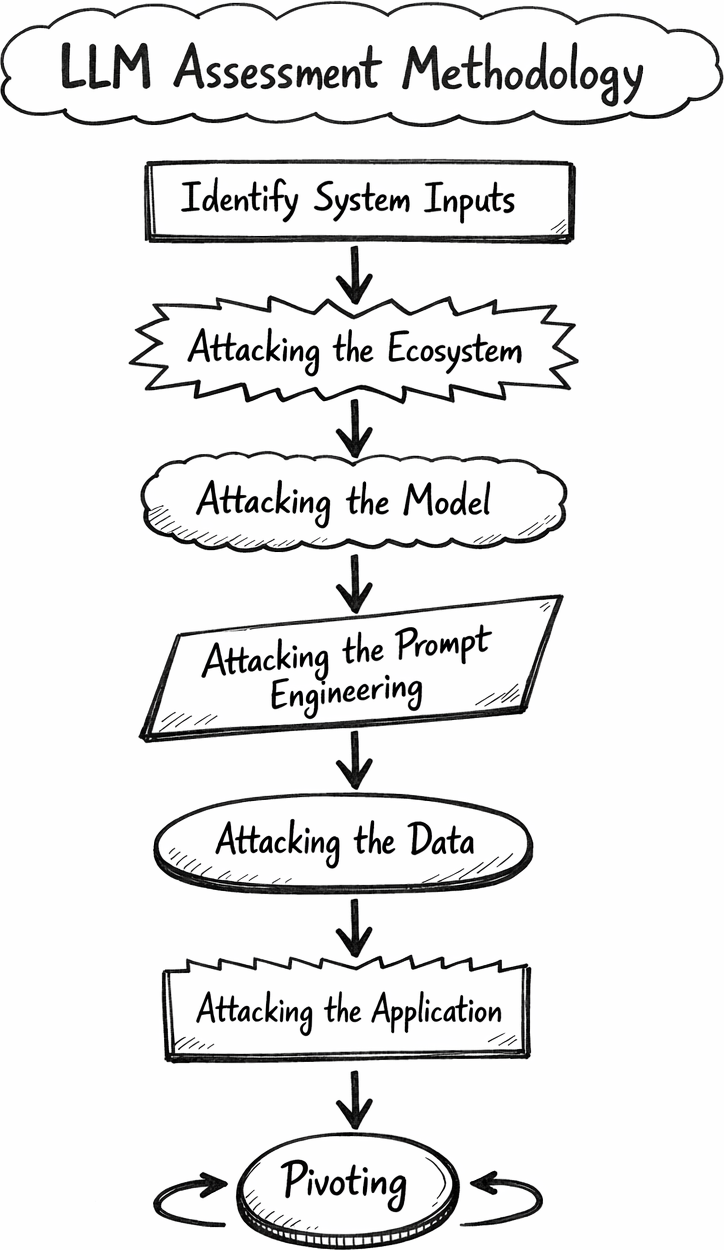
This is still a new space in the industry and so far there are only a couple of methodologies out there we can follow. As AI penetesting becomes more popular, I expect to see further methodologies come to fruition, digging deeper into the areas of AI penetesting.
Now that we have threat modelled and have some methodologies we can use, it's on to assessing the implementation. I'll keep this section fairly brief as there are a whole host of attacks throughout these models and i'll dig into those in future posts.
In most current cases when testing LLM integrations, we will see a web application enabled by LLM. As this is the case, we might look for some of the following inputs:
There are a whole host of other inputs we might see, such as indirect inputs (think Copilot and it's integrations into email, sharepoint, teams, graph etc). Some of these inputs will use traditional web methodologies of testing, while others will be via a form of direct or indirect prompt injections.
AI ecosystems introduce further attack surface outside of the typical chat windows and LLM integrations. When we look at attacking the ecosystem we are looking at the surrounding infrastructure that is present with hosting a LLM based service. This might take form as one (or more) of the following:
There are several ways in which we can attack the backend infrastructure, for example, prompt injection that leads to blind XSS, path traversals, auth bypasses, SSRF etc. These web vulnerabilities in systems that surround the LLM can be used to pivot through the LLM and into an organisation.
When we talk about attacking the model, we turn back to the AI red teaming phase. This is where we typically attempt prompt injections and/or jailbreaks to get the model to illicit bias or harm (for example, getting it to provide tutorials on how to do naughty things, like making bombs). Frontier models such as Claude are getting harder to prompt inject or jailbreak due to their continuously updated protections, but custom models are more prone to these types of attacks.
When attacking the model we also need to understand what guardrails are in place, be it at the prompt level of the LLM, or some form of security around the model. There are a whole bunch of evasion techniques that can be used to get around these, maybe we can explore those in a future blog post!
In this phase we are looking to leak any system or developer prompts from the model. These prompts contain valuable information that provides us with an understanding of how the model works. By performing prompt injection to get the system or developer prompts, we can expose any security implementations, sensitive internal data like URL's or API keys, API endpoints etc. If you're interested to learn more about how we might extract this information and bypass any security implementations, Jason Haddix has created the Arcanum PI Taxonomy, which has a whole host of valuable information used for prompt injecting LLM's:
https://arcanum-sec.github.io/arc_pi_taxonomy/
This is an important part of the assessment as it's where we start to go after sensitive company data. This could be customer data, employee information, intellectual property, technical specs etc. We are slowly seeing implementations of LLM's integrated with data stores and data retrieval systems. This could take the form of a database, S3 buckets, RAG vector stores and API endpoints and we have a number of opportunities:
This part is where we start to see traditional web vulnerabilities come into play. AI Ecosystems are more frequently using applications as part of their stack now and as such this opens up the attack surface to traditional attacks, such as:
To name a few. If we can find and exploit these vulnerabilities, it leads nicely into the final part of the methodology, which is to pivot through the model and into the organisation.
Once you can influence the model’s output, you can often influence the systems it has access to, internal APIs, plugins, retrieval systems, SaaS tools, and automation agents. This turns prompt injection from a “weird AI bug” into a lateral movement vector.
In mature environments, the LLM becomes a soft entry point into hard systems, data stores, ticketing systems, email, CRM, code repositories, and internal knowledge bases. The real impact of an AI compromise is therefore not misinformation, it’s unauthorised actions and lateral movement deeper into the organisation. That’s the pivot that organisations are currently underestimating, and it’s why AI testing must be treated as application and infrastructure security, not just model safety.
AI systems are not just models, they are complex ecosystems made up of models, prompts, data pipelines, APIs, plugins, agents, and internal integrations. When organisations deploy an LLM, they are not just deploying a chatbot, they are deploying a new interface to their internal systems and data.
That interface can be manipulated, influenced, and abused in ways traditional applications cannot. If we do not test these systems thoroughly, we risk creating highly trusted, highly connected systems that can be socially engineered through text alone. Penetration testing AI ecosystems is therefore not a niche exercise, it is a necessary evolution of application security. The organisations that understand this early will prevent the next generation of breaches, while those that treat AI as just another feature will end up exposing their internal systems through the very technology they adopted to move faster.
I hope this has given some insight into the ways in which we can test these fast moving AI integrations. More to come soon!

February 19, 2026

